A main() függvény sztring mutatók tömbjében kapja meg ezeket:
int main(int argc, char *argv[])
{
…
}
pozíció
tartalom
argc
számuk: 3
argv[0]
név: "teszt.exe"
argv[1]
p1: "elso"
argv[2]
p2: "masodik szo"
argv[3]
NULL
Az argc az argumentumok száma a program nevével együtt, argv a paraméterek tömbje.
Az argv[] a sztringeket tartalmazza (egy mutatókból álló tömb, amelynek mutatói
a sztringek elejeire mutatnak).
Az argv[] tömb a program neve, vagyis a futtatható fájlé, amilyen néven
a programot elindítottuk. Emiatt az első paraméter nem a nulladik, hanem az első indexen van stb.
Ugyancsak emiatt az argc értéke eggyel több, mint a tényleges paraméterek; a fenti
hívásban pl. kettő tényleges paramétert kap a program, és emiatt az argc értéke 3.
Fontos: ha számokat veszünk át paraméterként, azt is sztringként kapjuk! Ilyenkor pl. atoi()
vagy sscanf() függvényhívással lehet számmá alakítani őket.
3 A program visszatérési értéke
A main() visszatérési értéke egy egész szám.
Átveszi az operációs rendszer, és átadja a programnak,
amely elindította a mienket.
A 0-val tudjuk jelezni, hogy minden rendben.
Bármi más pozitív szám: általunk meghatározott hibakód.
int main(int argc, char *argv[])
{
if (argc-1 != 2) {
printf("Két paraméter kell!\n");
return 1; // hibakód
}
/* … a program tényleges dolgai … */
return 0; // minden oké
}
Példa az argumentumokra és a main() visszatérési értékére:
#include <stdio.h>
int main(int argc, char *argv[])
{
int egyik, masik;
/* 1-gyel tobb, mint a parameterek */
if (argc-1!=2) {
printf("%s: ket szamot adj meg!\n", argv[0]);
return 1; /* nem ket parameter van: 1-es hibakod */
}
if (sscanf(argv[1], "%d", &egyik)!=1) {
printf("Hibas elso parameter: %s!\n", argv[1]);
return 2; /* 2-es hibakod: hibas parameter */
}
if (sscanf(argv[2], "%d", &masik)!=1) {
printf("Hibas masodik parameter: %s!\n", argv[2]);
return 2;
}
printf("Az osszeguk: %d\n", egyik+masik);
return 0; /* 0-s kod: minden rendben, feladat elvegezve */
}
4 Fájlok kezelése
Az stdio.h-ban megadott FILE* típusú pointerrel és függvényekkel.
Megnyitás módja: írás (w) v. olvasás (r), szöveges (t) v. bináris (b).
Az fopen() visszatérési értéke: hivatkozás a nyitott fájlra.
Sikertelen megnyitásnál értéke: NULL pointer – ezt ellenőrizni kell.
Windowson az elérési útban \ az elválasztó: C:\Windows\hatter.bmp, Unixon / van:
/usr/bin/firefox. Az fopen() mindig elfogadja a /-t. Ha a \-hez ragaszkodunk,
azt viszont \\-nek kell írni a sztring belsejében, mivel a \ önmagában a speciális
karaktereket jelöli (pl. \n).
Létezik még két további megnyitás mód is:
hozzáfűzés (a). Ilyenkor a fájlt írásra nyitjuk meg, de
a meglévő tartalmát meghagyva. Az írás mutató a fájl végére mutat,
vagyis a meglévő tartalomhoz hozzáadva lehet folytatni az írást.
írás-olvasás (+). Ilyenkor írni és olvasni is lehet.
Más betűkkel együtt használjuk: pl. r+ azt jelenti, hogy a fájl
tartalma megmarad, de írni is lehet bele.
A szövegfájlokat a printf() és a scanf()
párjával, az fprintf()-fel és az fscanf()-fel
lehet kezelni. Ezeknek első paramétere a megnyitott fájl, a folytatás
pedig ugyanúgy van, mint a képernyő / billentyűzet párjuknál.
A szövegfájlokat lineárisan kezeljük, nem ugrunk benne ide-oda.
Bár elvileg lehetséges, de nehéz megvalósítani az adott sorra ugrást:
ki kellene számolnunk a bájtban megadott pozíciót. Azt meg nem ismerjük,
amíg nem olvastuk be a sorokat, mert minden sor különböző hosszúságú
lehet.
5 Hogy néz ki egy szövegfájl?
Egyes rendszerek máshogy jelzik a szövegfájlokban a sorok végét (\n).
Windowson két bájt, CR LF (0x0D 0x0A), Unixokon csak LF (0x0A).
Szöveges módban nyitott fájlnál ezt megoldja helyettünk a C.
Kezelés: fp=fopen(név, "…t"), fprintf(fp, …), fscanf(fp, …).
Ha az előző dián látható programot lefuttatjuk Windowson és valamilyen
Unix operációs rendszeren, akkor két különböző fájlt kapunk, a fent látható módon.
Ezt az adatmegjelenítést úgy nevezik, hogy „hexa(decimális) dump”. Bal oldalon a bájtok
értéke hexadecimálisan, jobb oldalon pedig a hozzájuk tartozó karakterek.
A vezérlőkaraktereket, vagyis az ún. nem nyomtatható karaktereket (mint az újsor
vagy a tabulátor) az utóbbiban ponttal szokták helyettesíteni.
A "t"-vel, szöveges módban megnyitott fájl olvasásakor és írásakor a
konverziót a C fájlkezelő függvényei automatikusan elvégzik. Vagyis Unixon
pl. a \n sortörést változatlanul kiírják a fájlba, Windowson viszont
a printf("\n") hatására nem egy, hanem két bájt kerül a fájlba.
Viszont az automatikus konverzió miatt ezzel nekünk nem kell foglalkozni, csak
annyiban, hogy "t" módban kell megnyitni a fájlt, ha szöveges
formátumot szeretnénk.
A fenti apróságtól eltekintve a szövegfájlok sokkal inkább hordozhatóak,
hiszen a bennük tárolt adatok nem függenek a számábrázolás módjától, amit az
adott géptípus hardvere határoz meg. Ez az oka annak, hogy az utóbbi években egyre
inkább terjednek a szöveg alapú formátumok:
szöveges dokumentumok: HTML, RTF, XML (DOCX)
adatok, adatbázisok: XML
6 Hogy néz ki egy bináris fájl?
struct adat {
char nev[13];
short eletkor;
} tomb[2];
fread(ptr, méret, db, fp), fwrite(ptr, méret, db, fp).
A ptr által mutatott memóriaterület olvasása/írása az fp fájlból/fájlba.
Az adat méret bájt méretű, db darabszámú elemekből áll.
Visszatérési érték a sikeresen olvasott/írt elemek száma.
Itt akad egy pár újdonság. Első a void* típusú mutató (az
fwrite() és az fread() első paramétere ilyen típusú).
Ez a pointertípus azt jelenti, hogy nincsen
meghatározva, milyen típusú elemre mutat az a pointer, hanem csak annyi,
hogy valahova a memóriába mutat. Az fread() és fwrite()
függvények azért várnak ilyen típusú mutatót, mivel nem foglalkoznak az általunk
megadott adatok értelmével – egyszerűen csak elvégzik a fájlműveletet.
Egy valamit azért mégis tudniuk kell az adatunkról, mégpedig azt, hogy hány bájtból
áll. Ezt a fordító meg tudja mondani: a
sizeof(típus) kifejezés megadja azt, hogy hány bájtból áll
a megadott típus. Ez kényelmes, egyrészt mivel nekünk nem kell fejben tartani,
másrészt a fordító úgyis jobban tudja. Ha átvisszük egy másik géptípusra a programunkat,
ott a sizeof(típus) értéke más lehet.
Az fread() és fwrite() második paramétere a típus méretét adja meg,
a harmadik paraméter pedig a darabszámot.
Ez a megoldás tömbök kezelésére kiválóan alkalmas: előbb
egy tömbelem mérete, utána a tömb elemszáma.
Az fwrite()
visszatérési értéke azt mutatja, hány elemet sikerült kiírnia, az fread()-é
pedig azt, hányat olvasott be. Ezek is „méret”, vagyis size_t típusúak.
(A size_t típus egy egész szám, azonban a mérete (bitszáma)
eltérhet az integerétől.)
Érdekesség.
A fenti sztringet 13 karakteren tároljuk, de a beírt sztring rövidebb. A
fennmaradó helyen memóriaszemét van – ezt a színezett
rész mutatja. Erről volt szó a sztringek kapcsán.
Külön érdekesség még, hogy van egy extra bájt is a struktúrában, a sztring
mintha 14 karaktert foglalna. Ez már nem tartozik a sztringhez, hanem egy
ún. kitöltő (padding) bájt. Ezt a fordító a sztring és a short
közé tette, valószínűleg azért, mert a processzor igényelte azt, hogy a
short párosadik bájton kezdődjön. Ha binárisan írjuk ki fájlba
az adatokat, ez is látszik.
Az is megfigyelhető, hogy ezen a gépen a
kétbájtos short típus helyiértékei fordított sorrendben vannak. Előbb az
alsó helyiérték: 4, utána a felső: 0. Ernőke életkora 4+0*256 év. Ez is az
adott számítógéptípus tulajdonságaitól függ, és egy olyan dolog, amely miatt
nem hordozhatóak egyik gépről másikra az ilyen gondolkodás nélkül, memóriatartalmat
egy az egyben kiírt bináris fájlok.
Ez a program az első paraméterében kapott nevű fájlról
egy másolatot készít, amelynek a nevét a második paraméterében kapja.
Az fread() a fájl végén 0-t fog adni (mert 0
bájtot olvasott be).
Az fwrite() visszatérési értéke azt jelzi, hány blokkot
írt ki; jelen esetben hány bájtot, mert egy blokk mérete 1 bájt (második
paramétere).
Természetesen a fájlmegnyitások sikerességét, illetve az írások
sikerességét is figyelni kellene, az előző diákon bemutatott módon.
Még az fclose() visszatérési értékét is
illene vizsgálni, mert a bezárás pillanatában is kiderülhet, hogy
hiba történt a fájlba írás közben. Ezek nem fértek fel a diára.
fprintf(stderr, "Nem sikerült megnyitni a fájlt!");
C-ben a szabványos kimeneti és bemeneti csatornákat
(adatfolyamokat, stream) is fájlként látjuk (második félévben ez elő
fog még kerülni). A normál printf(…) függvény
egyenértékű egy fprintf(stdout, …) hívással, a
scanf(…) pedig egy fscanf(stdin, …)
hívással. Az stdin neve szabványos bemenet (standard
input), az stdout-é szabványos kimenet (standard
output), az stderr-é pedig szabványos hibakimenet
(standard error output).
A szabványos hibakimenet (stderr) a normál
kimenethez hasonló a programunk számára. A kettő közötti különbség
az, hogy a normál kimenetre a program által előállított eredményt,
kimeneti adatot szokás írni, a hibakimenetre pedig a hibaüzeneteket.
Így elkerülhető, hogy a kettő egymással keveredjen, ha a kimeneti
adatokat egy fájlba szeretnénk irányítani, vagy egy másik programnak
átadni.
Fájlkezelés – további függvények és változók
Lásd a C puskát!
fseek(fp, pozíció, honnan) Ugrás a bájtban megadott pozícióra. A honnan értékei:
SEEK_SET=elejétől, SEEK_END=végétől,
SEEK_CUR=aktuális pozíciótól számolva.
ftell(fp) Az aktuális pozíció lekérdezése (bájtokban).
fputc(c, fp), fgetc(fp) A putchar() és getchar() párja.
fputs(str, fp), fgets(str, méret, fp) A puts() és a gets() párja.
errno Globális változó, ami a legutolsó hiba kódját tartalmazza.
feof(fp)! Megmondja, hogy fájl vége volt-e sikertelen az előző olvasás. (Nem használjuk!)
Vigyázat! Az feof()
függvény kicsit problémás, rendszeresen helytelenül szokták
használni. Ugyanis ez a függvény nem azt jelzi, hogy a fájl
végén tart-e az olvasás, hanem azt, hogy az előző sikertelen
olvasási művelet a fájl végének elérése miatt történt-e. Az
feof()nem jóstehetség! Nem fogja előre jelezni a fájl
végét. Csak akkor ad igaz értéket, ha már bekövetkezett
(múlt idő!) egy sikertelen olvasás. Ezért a while(!feof(fp))
fejlécű ciklusok teljesen bizonyosan hibásak. Az feof() helyett
a beolvasást végző függvények: fscanf(),
fread(), fgets(), fgetc() visszatérési
értékét kell figyelni.
Az előfeldolgozó
10 A preprocesszor
A C fordítás menete
Előfeldolgozás: az előfeldolgozó (preprocessor)
kezeli az # preprocesszor
direktívákat, illetve távolítja el a kommenteket.
Tényleges fordítás: a gépi utasításokká alakítás.
Az előfeldolgozó utasításai #-tel kezdődnek és a sor végéig tartanak.
Nem kell a végükre pontosvessző.
Az előfeldolgozó további feladatai
Egy sorba fűzi a \ karakterrel több sorban megadott forráskódot.
Vagyis ez a kettő egyenértékű:
printf("\
hello\
hello");
printf("hellohello");
Összefűzi a közvetlenül egymás mellett álló sztring konstansokat:
"Hello" "vilag" = "Hellovilag".
Kicseréli az ún. hármas karaktereket (trigraph) a megfelelő párjukra.
A C megengedi, hogy egyes írásjeleket, pl. [], <> stb. más
karakterekkel helyettesítsünk. Ennek célja az, hogy lehessen olyan billentyűzeten
is C programot írni, amelyeken ezek nincsenek – látszik, hogy ez egy nagyon
régi, mára elavult lehetősége a nyelvnek. Ez egy helyes C program:
A csere sztringeken és kommenteken belül is megtörténik.
Egy sztringben lévő egymás utáni két ?? karakter
hatására ez aktiválódhat, azért fontos tudni róluk.
Manapság kódot így nem szokás írni,
sőt egyes fordítóknak külön jelezni kell, ha kérjük
ezeket a helyettesítéseket.
Ha nem zárójelezzük a makrókban a paramétereket,
akkor az operátorok precendeciái miatt a kifejtett C kódrészlet
mást jelenthet, mint amire számítunk. Ezért azokat mindig kötelező
zárójelezni! A többlet zárójelekből baj nem lehet.
Buktató II.: ha olyan makrót írunk, amelyik többször is kiértékeli
valamelyik paraméterét, akkor nem szabad mellékhatással rendelkező
kifejezést megadni neki! Különben a következő probléma adódhat:
#define MAX(A,B) ((A)>(B)?(A):(B))
printf("%d", MAX(++a, ++b)); /* nem jó ötlet… */
printf("%d", ((++a)>(++b)?(++a):(++b))); // előfeldolgozva
„A makrókkal kapcsolatban az első szabály: ne használjuk őket, ha nem muszáj.” – Bjarne Stroustrup
Érdekesség: Bjarne Stroustrup dán programozó. Ő találta
ki a C++ nyelvet, amely a C-nek a továbbfejlesztése. Második félévben lesz tananyag a Prog2 és a
Szoftlab2 tárgyakból.
12 Feltételes fordítás: #if, #ifdef, #ifndef
#ifdef, #ifndef – ha definiálva van a makró
#ifdef TESZT
/* csak tesztelés közben */
printf("x=%d", x);
#endif
Egy feltételtől függően lefordítja, vagy kihagyja az adott részt.
Ez is arra való, hogy kihagyjuk vagy beillesszünk részeket.
Itt arra használjuk, hogy a használt grafikus könyvtár
verzióját ellenőrizzük; ha nem megfelelő, akkor megállítjuk
a fordítást a megadott hibaüzenettel.
#pragma – nem szabványos kiterjesztések
A fordítók saját, nem szabványos kiterjesztései. Ha egy fordító nem érti a #pragma sort, figyelmen kívül hagyja. Pl.
#pragma omp parallel for schedule(dynamic) /* OpenMP */
for (y=0; y<magassag; y++) {
…
OpenMP: az ezt ismerő fordítóknak megadhatjuk, hogy egy
ciklus iterációit szétossza a gépben lévő processzorok (magok)
között.
Mivel semelyik #pragma nem lehet szabványos
(éppen az a célja, hogy jelezze a fordítónak, nem szabványos dolgot
írunk be), ezért a #pragma once használata tilos.
A fejlécfájlok többszöri feldolgozása ellen az #ifndef+#define
technikát kell használni, amelyet minden fordító felismer.
Többmodulos programok
14 Nagy projektek: egy fájl? több modul!
„MLOC project” million lines of code
Egy közepes projekt néhány tízezer sorból áll,
egy nagy projekt több százezer, akár millió sorból.
A programot szerkezeti egységekre, modulokra kell bontani.
struct Tort, tort_osszead(), tort_szoroz()… – ez lehet egy modul.
Ha a projekt egyetlen, nagy forrásállományban lenne megírva:
akkor áttekinthetetlen lenne,
a szerkesztő programok nehezen/lassan kezelnék,
nehézkes lenne többen egyszerre dolgozni rajta,
egy-egy újrafordítás akár órákat vehetne igénybe.
Ha szerkezeti egységekre bontjuk a programot:
ezek önállóan fordíthatóak, a program ezek összeépítéséből lesz,
egy csapat különböző tagjai egymástól függetlenül dolgozhatnak,
az egyedi fordítások gyorsan lezajlanak.
Ez az egyedül fejlesztett programoknál is nagyon hasznos:
az egyes modulok újra felhasználhatóak más projektekben.
Érdemes a funkcionális egységeket általános módon
megírni, hogy minél könnyebben fel lehessen használni őket más feladatok
megoldásában.
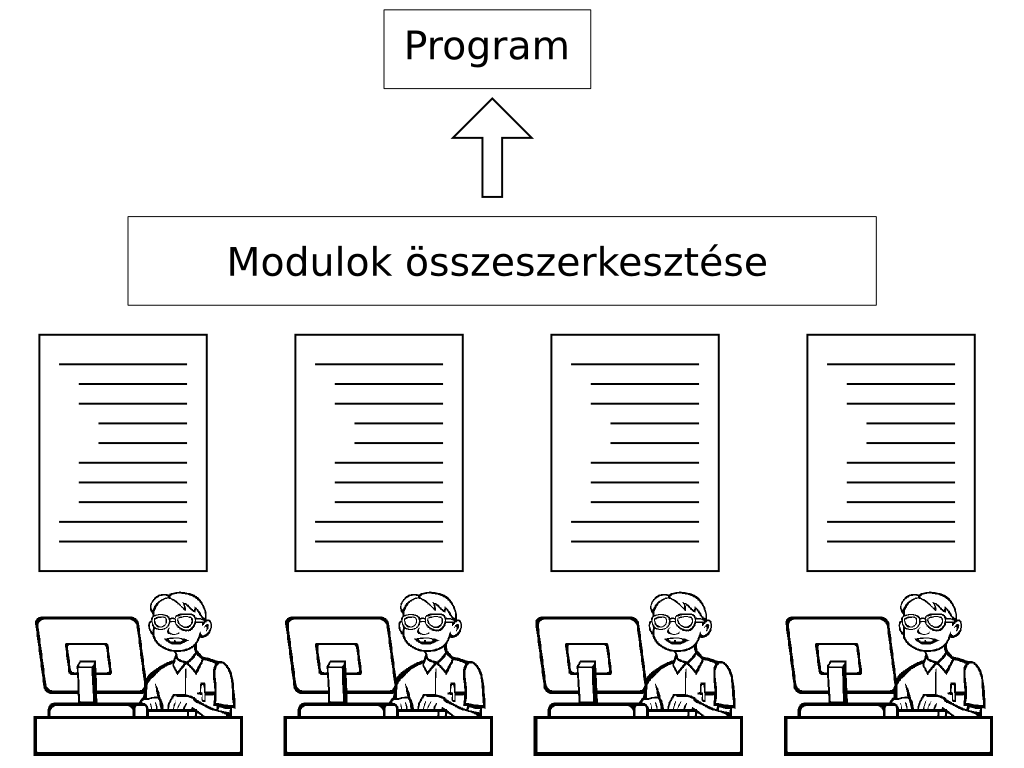
15 Fordítás és linkelés
A futtatható program előállítása valójában mindig két lépésből áll:
a forráskód lefordítása (compile) tárgykóddá (object code),
a tárgykódok összeszerkesztése (link) futtatható programmá (executable).
A tárgykód olyan gépi kódú program, amelyben hivatkozások vannak
(változónév, függvénynév) másik modulban lévő elemekre.
Így csak az összeszerkesztéskor kell őket feloldani.
A fordító neve angolul: compiler, a szerkesztőé: linker.
typedef struct Szakasz {
double x1, y1, x2, y2;
char szin[20+1]; // pl. "red"
} Szakasz;
Kép: méret, pozíció (origó), nagyítás és a szakaszok.
enum { SZAKASZ_MAX = 2000 };
typedef struct Rajz {
int kx, ky; /* kép mérete */
double ox, oy; /* origó pozíciója a képen */
double nx, ny; /* nagyítás */
int db;
Szakasz szakaszok[SZAKASZ_MAX]; /* szakaszok tömbje */
} Rajz;
A terveink a következők. A megrajzolt függvényekhez egy csomó szakasz
tartozik. Ezek különböző színűek is lehetnek. Eltároljuk őket egy tömbben.
De nem csak ezek a szakaszok tartoznak a képhez, hanem annak vannak egyéb
tulajdonságai is: tudni kell, mekkora (kx, ky), hol van rajta az origó (ox, oy)
és hogy mekkora a nagyítása (nx, ny). Az utóbbi azt jelenti, hogy a monitoron
hány képpont jelenti a matematikai koordinátarendszerben az egységet. Ha mindezek
megvannak, akkor egy függvény kirajzolható.
Ezek alapján a rajz struktúra tartalmaz egy szakaszokból álló tömböt.
Az egyes rajzokon eltérő számú szakasz lehet, így a darabszámot is felvesszük
emellé. Meg kell becsülnünk azt is, hány szakaszból állhat egy rajz; itt
azt mondtuk, 1000-nél több ez nem lehet. (Későbbi előadásokon majd lesz szó
arról, hogy az ilyen előnytelen, ex-has becslések helyett milyen megoldásokat
tudunk alkalmazni.)
Nyíl operátor: a pointer által mutatott struktúra adattagja:
(*pr).kx = 160;
pr->kx = 160; // ugyanaz!
Dereferál és mezőt kiválaszt. Nem kell zárójelezni!
A lényeg röviden: ha struktúrából egy mező kell, akkor ponttal választjuk
ki. Ha pointer van a struktúrára, akkor pedig nyíllal.
A nyíl operátort azért találták ki, mert a . mezőkiválasztó
operátornak magasabb a precedenciája, mint a * dereferáló operátornak.
Ha ennyit írnánk: *pr.kx, akkor azt a . magasabb
precedenciája miatt *(pr.kx)-ként próbálná meg értelmezni a fordító,
ami viszont nyilván nem lehetséges, hiszen pr nem struktúra, hanem pointer,
amelynek nincsenek mezői. Ha nem lenne a nyíl operátor, akkor minden ilyen hozzáférést
zárójelezni kellene, mint ahogyan az fent a buborékban is látszik.
Struktúrákra mutató pointerek esetén mindig ezt használjuk, mert egyszerűbb,
olvashatóbb kódot kapunk, mintha zárójelezni kellene. (Ahogyan az indexelő
operátor esetén: tomb[i] helyett sem írunk *(tomb+i)-t,
mert nehézkesebb, bonyolultabb, és semmivel nem jobb, mint az indexelő operátoros
forma.)
20 Függvényrajzoló: a rajzolás maga
Tervezzük meg az algoritmusokat! Legfontosabb a függvény kirajzolása – ezzel foglalkozzunk.
A monitoron és a képeken más koordinátarendszert szokás használni (origó bal felső sarokban, x jobbra, y lefelé),
mint a matematikában (origó középen, x jobbra, y felfelé). A rajzaink nagyítása is változhat.
Ezért praktikus függvényeket írni, amelyek ezen koordinátarendszerek között a transzformációt
elvégzik, mert így bármikor át tudunk térni a képbeli koordinátákról a matematikai
koordinátákra és fordítva. Ezek a függvények a kep2mat() és a mat2kep().
Ezek segítségével már könnyű megvalósítani a függvény ábrázolását. A rajzolást,
ha a kép koordinátarendszerében végezzük, akkor biztosak lehetünk abban, hogy nem lesz
túl cakkos sem a függvény (mint az előző képen), de nem is számoljuk ki feleslegesen
sok pontban (olyan sűrűn, hogy már nem is látszik a különbség – ez csak foglalná
feleslegesen a memóriát, és megtelne a szakaszok tömbje).
Ezért a kép koordinátái szerint haladunk egyesével; előbb átalakítva
a képkoordinátarendszerbeli x-et matematikai koordinátává, ami a
függvénybe behelyettesíthető. Az így kapott matematikai y koordinátát utána
képbeli y koordinátává alakítva megkapjuk az SVG fájlba írandó szakasz
koordinátáit.
A görbe megrajzolásának algoritmusa mindig ugyanaz.
void fv_rajzol(Rajz *r, double (*pfv)(double), char const *szin) {
…
for (xk = 0; xk <= r->kx; xk += lepes) {
…
y = pfv(x); // a paraméterként kapott függvény hívása
…
}
Pointer, ami egy függvényre mutat. Paramétere: egy double,
visszatérési értéke is egy double.
double (*pfv)(double);
A fenti negyzet() függvénynek is ilyen az aláírása,
és a math.hsin() függvényének is. Bármelyik
egyéb, ugyanilyen aláírással rendelkező – egy double
paraméterű, double visszatérési értékű – függvényt képes
így ábrázolni a rajzoló!
A függvényekre mutató pointerekről egy későbbi előadáson lesz szó.
Most csak említésképp szerepelnek; a NZH-ban még nem lesz ilyen.
A programot két modulra lehet bontani.
Az első a fő programmodul. Ez tartalmazza a main() függvényt,
a menu() függvényt, és az ábrázolandó parabolát kiszámoló függvényt is.
A másik modul a függvények megjelenítését tartalmazó programrészekből
áll össze. Érezhető, hogy ez egy külön egység, amely önmagában is
megállja a helyét. Lehetne egy teljesen másik programot is írni, és
abban ugyanezt az ábrázolót használni.
Az ábrázoló függvényeit ezen belül tovább lehet bontani két csoportra.
Azok a függvények, amelyek az ábrázoló modul használója számára
is fontosak, például a rajz_inicializal() és a
fuggveny_rajzol(). Ugyanebbe a csoportba tartozik
a függvények mellett a Rajz nevű típus, hiszen
ezt is ismernie kell annak, aki használni szeretné. Definiálnia
kell tudni Rajz típusú változót!
A másik csoportba olyan függvények tartoznak, amelyek a használó
számára nem lényegesek, sőt jobb ha nem is kell foglalkoznia velük.
Ezek például a koordinátarendszer-transzformációt végző
kep2mat() és mat2kep() függvények.
23 A két modul forrásfájljai
A végleges program a két forráskód összeszerkesztéséből
fog keletkezni.
fuggveny.c: az ábrázoló
/* más modulból NEM látszó függvény: static */
static void kep2mat(Rajz *r, ………) {…}
static void mat2kep(Rajz *r, ………) {…}
static int szakasz_rajzol(Rajz *r, ………) {…}
/* más modulból is látszó függvények */
void rajz_inicializal(………) {…}
void rajz_torol(………) {…}
int fuggveny_rajzol(………) {…}
main.c: a főprogram
static double parabola(double x) {…}
static int menu() {…}
int main() {…}
A programot a fentiek alapján két külön forrásfájlra bonthatjuk.
A függvények elé írt static kulcsszó azt mondja, hogy az
a függvény csak abból a modulból (abból a forrásfájlból) kell elérhető
legyen, máshonnan nem. Vagyis pl. a main.c-ből nem lehet
majd meghívni a kep2mat() függvényt. De nincsen is rá
szükség. Elég, ha ennek a függvénynek a láthatóságát (scope)
a függvényábrázoló modulra korlátozzuk.
Az ábrázoló modul többi függvényei viszont elérhetőek
kell legyenek a main.c-ből, hiszen a főprogram meghívja
őket.
24 Deklarációk és definíciók
A main.c fordításakor a fordítónak rengeteg
deklarációra van szüksége:
Vagyis fogjuk az összes olyan típust és függvényt,
amelyeket láthatóvá szeretnénk tenni a
többi modul számára, és készítünk belőlük egy
fuggveny.h nevű fejlécfájlt a
fuggveny.c modul mellé.
Mi kerül a forrásfájlba (.c), és mi kerül a fejlécfájlba (.h)? Ez
egyszerű: a kódfájlokba (.c) mennek a függvények definíciói, a
fejlécfájlokba mennek a függvények deklarációi. Persze csak azok,
amelyeknek máshonnan is látszaniuk kell, másik modulból. A statikus
függvényeket, amelyek csak az adott modulból látszanak, nincsen
értelme (sőt: hiba!) szerepeltetni a fejlécfájlban, hiszen azok a
statikus jellegük miatt amúgy sem érhetők el máshonnan. Ugyancsak a
fejlécfájlokba mennek a kívülről is használható típusok
definíciói.
Ezt a fejlécfájlt a többi modul, amely szeretné használni a függvényrajzoló modul
szolgáltatásait, beilleszti a saját forráskódjába az #include "fuggveny.h"
sorral. Így a fordító érteni fogja, mi az, hogy Rajz, és azt is fogja tudni,
hogy létezik a rajz_inicializal() függvény, ismeri a paramétereinek
típusait és így tovább. Le tudja fordítani a kódot!
Fontos, hogy a fejlécfájlt nem csak a többi modulnak kell beillesztenie,
hanem annak a modulnak is, amelyhez tartozik. Vagyis jelen esetben a
fuggveny.c-nek is include-olnia kell a fuggveny.h-t! Ennek oka
kettős: egyrészt a függvényrajzoló kódjának is ismernie kell a hozzá tartozó típusokat
(Szakasz, Rajz), másrészt pedig így biztosítható az, hogy
a modul forráskódjában nincsenek véletlenül hibásan megadva a függvények paraméterei. Ha
a forrásfájlban más fejléccel definiálunk egy függvényt, mint a fejlécfájlban, akkor az
a projekt fordításakor hibához vezet. Ha beillesztjük minden modulba a saját fejlécfájlját
is, akkor ezeket a hibákat a fordító megtalálja!
Az #ifdef és #ifndef direktívákkal
ellenőrizni tudjuk, hogy definiálva van-e egy makró, és
attól függően egy programrészt teljesen kihagyhatunk
a fordításból.
Jelen esetben ezt arra használjuk, hogy biztosítsuk azt,
a függvények ne legyenek többször deklarálva. Összetett
projektek esetén ugyanis a fejléc fájlok általában egymást
is betöltik (include).
A fenti preprocesszor direktíva úgy működik, hogy az első
betöltéskor még beilleszti a kódot, mivel a FUGGVENY_H_BEILLESZTVE
makró ilyenkor még nincs definiálva: #ifndef. De egyből
definiálja is, vagyis másodjára már az egész kódrészlet kimarad.
26 Függvényábrázoló – függőségek és fordítás
A kész programunk most három lépésből állítható elő:
Le kell fordítani a függvény modult. Ebből egy tárgykód fájl keletkezik.
Le kell fordítani a főprogram modult is. Ebből is egy tárgykód lesz.
Végül pedig a két tárgykódot össze kell szerkeszteni.
Az összeszerkesztéskor (linking, „linkelés”) nem csak az általunk írt függvényeinket,
hanem a szabványos C könyvtári függvényeket (printf(), sin() stb.)
is megkeresi a linker.
A három műveletet az itt látható parancsok begépelésével lehet elvégezni Linux
rendszeren. Windowson is hasonlóképpen működik.
A fordítási és szerkesztési lépéseket egyébként az integrált fejlesztőkörnyezetek
automatikusan elvégzik, azt ritkán kell parancssorból, kézzel végeznünk: a
laboron használt Code::Blocksban is csak egy kattintás, és indul is a lefordított programunk.
Ugyancsak automatikusan végzik a fejlesztőkörnyezetek a függőségek feltérképezését.
Figyeljük meg az ábrán: az egyes fájlok módosítása esetén nem kell mindegyik műveletet
újra elvégezni. Például ha a main.c fájl tartalmát szerkesztjük, akkor
nincsen szükség a fuggveny.c újbóli fordítására, hiszen azon lépés által
keletkező fuggveny.o fájl tartalma nem függ a main.c
tartalmától. Szükség van viszont a main.c fordítása után
az újbóli linkelésre is, hiszen a megújult main.o-tól függ a végleges
programfájl, a fuggveny tartalma. Így végeredményben egy
fordítást tudunk megspórolni ebben az esetben.
Nagyobb projekteknek ennél sokkal bonyolultabb függőségi gráfjuk van. A függőségek
figyelembe vételével könnyen meghatározható az, hogy egy adott fájl módosítása esetén
mely fordítási, linkelési lépéseket lehet elhagyni. Minél kisebb részekre, fájlokra van
bontva a projekt, annál kisebbek lehetnek az újból elvégzendő lépések, hiszen annál több
fájl marad változatlan egy kisebb módosítás esetén.
27 Modulok: globális változók
A függvényeken kívül definiált változók: globális változók.
Ezeket minden függvény eléri.
Ezeket is megoszthatjuk modulok között.
A változódefiníciók a modulokba kerülnek.
A deklaráció az extern kulcsszóval történik. (Enélkül definíció lenne!)
Statikus változó globálisan: csak az adott modulban látszik.
int megosztott=5;
static double szorzo;
modul.c
extern int megosztott;
modul.h
#include "modul.h"
int main()
{
int a, b = 7;
a = b + megosztott;
…
foprogram.c
A globális változókat nem szoktuk szeretni, ugyanis nehezen áttekinthetővé
teszik a programot. Mivel mindegyik modulnak van hozzáférése a globális
változókhoz, nem lehet tudni, melyik működése függ attól, és hogy
melyik fogja azt módosítani. Ha a függvényeknek mindent paraméterben
adunk át, akkor tiszta: csak az lehet a bemenő adat, ami paraméter, és
csak az a kijövő adat, ami a visszatérési érték.
Itt jól látszik, mit jelent változók esetén a deklaráció és a definíció:
deklaráció, amikor megmondjuk a típusát, definíció, amikor memóriát is
foglalunk hozzá. Az extern-nel kezdődő sor csak deklaráció. Azt
mondja a fordítónak, hogy van valahol egy ilyen nevű és ilyen típusú változó
egy másik modulban; az összeszerkesztéskor majd elő fog kerülni.
28 Modulok: statikus, lokális változók
Olyan lokális függvényváltozót tudunk így létrehozni, amely
a függvény első hívásakor jön létre,
értékét megőrzi a függvényhívások között,
ugyanakkor lokális, tehát kívülről nem érhető el.
1 2 3 4 5
int hanyszor_hivodott()
{
static int db=0; // inicializálás csak először!
return ++db;
}
int main()
{
int i;
for (i=0; i<5; ++i)
printf("%d ", hanyszor_hivodott());
…
A függvényen belüli statikus változót is értelmezhetjük
úgy, mint az előbbit: ez egy olyan globális változó, amely
csak a függvényen belül látszik. (Ennek ellenére a függvények
statikus változóit nem szokták globálisnak nevezni.)
Ezt a funkciót nagyon ritkán használjuk. Nem is igazán ajánlott ilyen
függvényeket írni, mert az olvashatóságot rontja, ha egy függvény
visszatérési értéke nem kizárólag a bemeneti paraméterek értékétől függ.
Sok beépített, könyvtári függvény használja azonban, ezért fontos, hogy ismerjük és
tudjuk, hogy mi történik a háttérben.
Ilyen például a strtok(), amely arra használható, hogy egy szöveget bizonyos
határoló karakterek mentén feladaraboljunk. Például a "Szia, ez itt egy proba.
Futtass le!" szöveget úgy darabolhatjuk fel szavakra, hogy határoló
karakterként megadjuk a következő karaktereket: ' ', ',', '.', '!'.
#include <stdio.h>
#include <string.h>
int main() {
char str[]="Szia, ez itt egy proba. Futtass le!";
char *pch;
printf("Az eredeti szoveg: %s\n",str);
pch = strtok(str," ,.!");
while (pch != NULL) {
printf("%s\n",pch);
pch = strtok(NULL, " ,.!");
}
return 0;
}
Látható, hogy az strtok függvény első hívásakor megadjuk a
feldolgozandó sztringet, de a későbbiekben már NULL pointerrel
hívjuk. Honnan tudja hát, hogy milyen szövegen dolgozzon? A másik talány
pedig az, hogy hogyan tudja megjegyezni, hogy hol tart a szövegben, hiszen
minden híváskor a soron következő szóval tér vissza.
Mindkét kérdésre a static változó a megoldás: amikor egy nem
NULL pointerrel hívjuk meg, akkor egy static char
* típusú változó értékében elmenti ezt a címet. Elkezd a
sztringgel dolgozni, visszatér az első szóval és a static
változó értékét beállítja a soron következő szó elejére.
A következő hívásnál NULL pointerel hívjuk, így tudja, hogy
folytatnia kell egy korábbi sztringet. A cím pedig, amivel dolgoznia kell,
el van tárolva a static változóban.
29 Láthatóság és élettartam: összefoglalás
modul.c
int globalis; // projektben globális
int globalis_fv(void) {
int lokalis;
static int statikus; // lokális, értékét megőrzi
…
}
static int statikus; // csak ebben a modulban
static int modul_fv(void) {
…
}
modul.h
extern int globalis; // globálisak deklarációi
int globalis_fv(void);
A láthatóságot a fenti kommentek jelzik. A változók
élettartamát is könnyű megjegyezni: a globális változók
a program futásának egész ideje alatt léteznek, a lokális
változók pedig csak akkor, amikor az őket létrehozó
függvényben van épp a végrehajtás.
A függvények statikus változói öszvérként viselkednek:
a láthatóságuk lokális, azaz a függvényre korlátozódik,
az élettartamuk viszont a globális változókéhoz hasonló.
Hiszen éppen úgy tudják megőrizni az értéküket a függvényhívások
között, hogy nem szűnnek meg a függvényből visszatéréskor.
Az assert.h-ban definiált makró megszakítja
a program futását, és hibaüzenetet ír ki, ha a paraméterként kapott kifejezés hamisra
értékelődik ki.
Ha definiálva van az NDEBUG makró, akkor üres
utasításra cserélődik – vagyis a program végleges változatát
már nem lassítják az ellenőrzések.
36 Tesztelés IV. – Ha maradna benne hiba…
„It's not a bug! It's a feature!”
37 Dokumentáció I.
A dokumentáció szintjei:
Fejlesztői dokumentáció
adatszerkezetek dokumentációja,
algoritmusok dokumentációja,
a kód szerkezeti áttekintése,
a kód részletes dokumentációja.
A forráskód
kommentezés! /* ajánlott: a kód 30%-a */
Felhasználói dokumentációja
a program használatának a leírása.
38 Dokumentáció II.
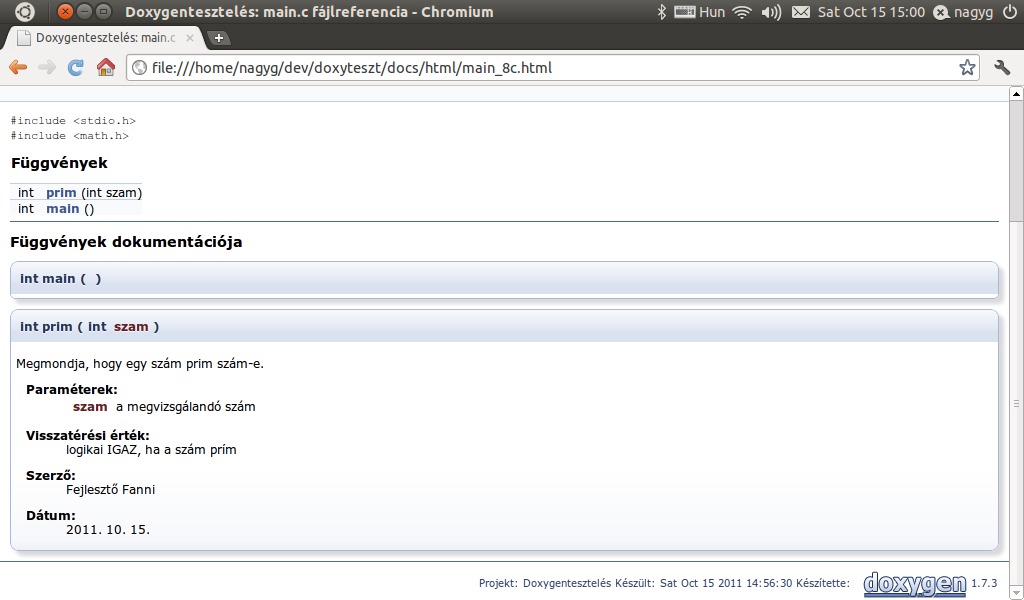
A dokumentációt támogató kiváló eszköz pl. a Doxygen.
A függvényrajzoló forráskódja végig ilyen
/**
* Megmondja, hogy egy szám prim szám-e.
* @param szam a megvizsgálandó szám
* @return logikai IGAZ, ha a szám prím
* @author Fejlesztő Fanni
* @date 2011. 10. 15.
*/ // Speciális megjegyzés!
int prim(int szam)
{
int oszto;
for (oszto=2; oszto*oszto<=szam; ++oszto)
if (szam%oszto == 0)
return 0;
return 1;
}